Overview
Wikipedia describes event based programming as follows:
"In computer programming, event-driven programming or event-based programming is a programming paradigm in which the flow of the program is determined by events"
In CLIP programs, the flow of the program is determined by events that are exchanged between CLIP's nodal objects. A CLIP circuit consists of many active objects that exchange information through stores and semaphores. After one method writes to a store and closes it, another method is triggered with a ready-to-read event and it is the connectivity between all of the nodes that determines the flow of control through the program.
When you make a connection from one object to another in the circuit diagram, you are telling the runtime that the consumer must subscribe to the provider's published event, and the attributes of that connection dictate the type of event that you are subscribing to (read, write, signal, request etc.).
What is a CLIP Event?
A CLIP event is a tree data structure (an Event Tree) that holds information about all the objects from which an active object consumes right back to the ultimate event providers (stores or semaphores). It is generated by a provider, travels along a connection, and is finally processed by a consumer.
What Information Do Events Carry?
Each node within the event tree provides details relating to a particular object. These details vary according to the type of object, but can include:
- Event Type
- Element number of the source object
- Link Number of the source object's connection
- Address of any data
- State(s) of the source object
Some of these details can be accessed by the connection's member functions (see below, and also the Connection Objects reference section for more detail). Every CDL connection has a name (by default this is derived from the provider name) and thus items in the event tree can be accessed via access functions with names based on the connection names.
How Are Events Generated and Consumed?
There are two different mechanisms for requesting event generation within a circuit:
Automatic Connections
An automatic connection is handled by the runtime without requiring any additional coding. For example, when a method is activated, it automatically requests an event through its trigger connection; when the event arrives it executes the method's processing code; and when the processing code function returns, it automatically closes the event and the cycle repeats:
 Click to enlarge
Click to enlargeConnections from passive objects are also automatic. When a collector receives an event request, it propagates a request to each of the objects that it is consuming from; when an event has arrived from each of them, the collector provides a compound event; and when that compound event is closed, all of the events provided to the collector are closed:
Manual Connections
Alternatively, manual connections must be requested and closed manually with additional user code. This allows multiple events to be consumed by a method, which is useful where it must write to an unknown number of buffers within a store, for example (if the number of writes is known then they can be collected automatically). All thread and interface connections are manual and all method connections (except for the trigger) are manual.
Requesting an event through a manual connection involves explicitly calling the request function of the connection (OpenRead(), WaitEvent(), Request() etc.). When the event is finished with, it is closed by calling Close().
How Are Events Queried for Their Information?
Event trees can be several levels deep and in order to access data in the leaf nodes it is necessary to traverse the intermediate objects that link the active object and its ultimate providers. Explicitly referencing the intermediate objects in your user code would tie that code to the structure of the circuit and make changing the circuit awkward, but most of the time you don't care about the intermediate objects and so you should be able to insert a new object in the tree without having to modify your user code. Fortunately, Blueprint provides access functions to query each object directly without having to traverse the tree (the access functions secretly traverse the tree but this code is auto-generated so that changes to the circuitry are reflected in the access functions automatically).
The following circuit shows a thread that consumes from a multiplexer, that in turn consumes from a store and a collector that consumes from two stores:
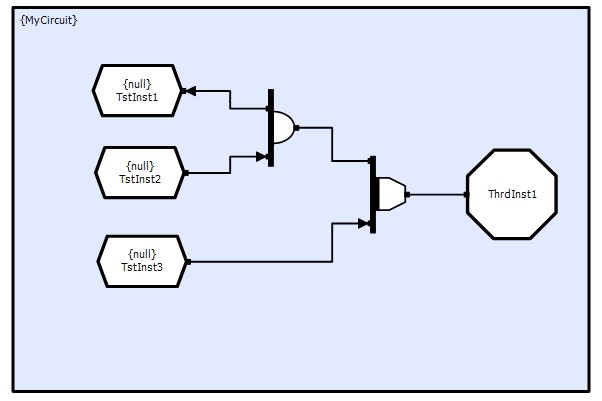
The following code retrieves the multiplexer connection; the connection number for the connection from the multiplexer to the collector; and the data record contained in the store TstInst1:
CLIP::MpxManCxn& cxn = this->Aux1_MpxInst1Mpx1Cxn();
Uns cxnNum = MyCircuit_MpxInst1Mpx1Cxn::ClxInst1Clx1_CxnNumber();
DataType& data = this->Aux1_TstInst1Tst1Rec();
The following code shows these calls in action. It waits on the multiplexer and depending on the link that fired, retrieves the appropriate data object(s) and processes them:
Uns MyCircuit_ThrdInst1ThrdElem::Process()
{
while ( TRUE )
{
// wait up to 1 sec for event
if ( this->Aux1_MpxInst1Mpx1Cxn().WaitEvent ( 1000 ) )
{
const Uns linkNum = this->Aux1_MpxInst1Mpx1Cxn().LinkNum ();
// collector - 2x data stores - read access and write access
if ( linkNum == MyCircuit_MpxInst1Mpx1Cxn::ClxInst1Clx1_CxnNumber () )
{
// construct output - copy input to output
this->Aux1_TstInst1Tst1Rec().Construct();
this->Aux1_TstInst1Tst1Rec().Data() =
this->Aux1_TstInst2Tst1Rec().Data();
}
// data store - read access
else if ( linkNum == MyCircuit_MpxInst1Mpx1Cxn::TstInst3Tst1_CxnNumber())
{
// if the store has been written to 10 times do something
if ( this->Aux1_TstInst3Tst1Cxn().NumWrites() == 10 )
{
Uns x = this->Aux1_TstInst3Tst1Rec().Data().X();
}
}
this->Aux1_MpxInst1Mpx1Cxn().Close();
}
}
return TRUE;
}
In the above code sample;
- Event Control is shown in red
- Event/State Interrogation is shown in green
- Data Access is shown in blue
Event-Flow and Data-Flow
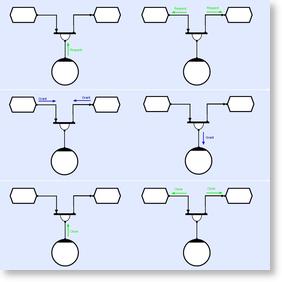
In the CLIP context, the term 'event' has a specific meaning and refers to an exchange of information along the connections that link object pairs. More specifically, event-flow is a different thing from data-flow. Data flows from writers to stores, and from stores to readers, whereas events flow from providers to consumers. Consider the figure below which shows a method collecting a read and a write to the 'input' and 'output' stores;
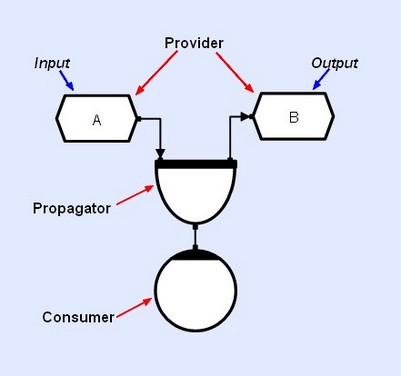
In this instance, the collector will asynchronously request a 'ready for write' event from the output store, and a 'ready for read' event from the input store. When both events are collected (there's a readable data buffer in the input store, and a spare writeable buffer in the output store), then the 'compound' event containing references to both buffers will travel to the method, causing it be scheduled to execute. The user code inside the method will then be passed references to the input and output buffers and execute. When the user code executes a return, the collector will automatically be closed, and this will then cause its providers (the two stores) to close, and if there are other methods waiting to read/write from the stores, they will execute in turn.
There are a number of points to note. Firstly stores can only provide events and cannot consume; and secondly, methods can only consume events and cannot provide; but methods, can read and write in a data-flow sense. Secondly, event operators like collectors, multiplexors and distributors will have one consuming face which can only be connected to one or more providers; and one providing face, which can only be connected to one or more consumers. This means that event flow direction is implicitly inferred from circuitry, but read/write direction requires the explicit use of arrows on connections. Events can therefore thought of as emanating from stores, propagating through an arbitrary composition of event operators, and then being destructively consumed by methods, call-backs and threads.
Finally, if the two objects are co-located in the same shared memory space then events are exchanged by reference, if they are in disparate memory spaces then all data associated with the event is transparently moved and cached (so that it is only moved once). Cached data is automatically deleted when it is no longer referenced. This also allows the scheduler to minimize network traffic by sending jobs to cached data, rather than the other way around (see jobs above).
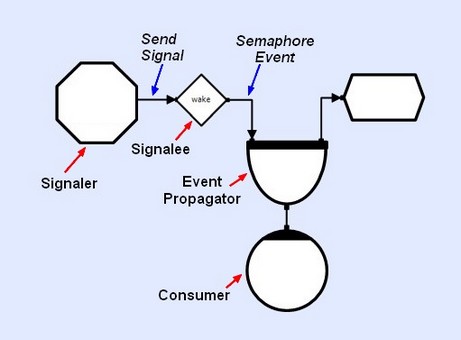
The Difference Between Events and Signals
Signal flow is distinct from data flow and event flow, and only applies to counting semaphores and logical semaphores. Signals are sent to semaphores, but unlike store writing, semaphore signaling is a non-blocking operation. Semaphores can be signaled from any active object (methods, threads and call-backs), and once signaled will usually generate a consumable event (depending on user parameters). As with read/write store connections, semaphore connections also require arrows to indicate whether they are being signaled, or consumed from. Signaling can be thought of as generating events within the semaphores, and semaphore consumers will typically block until the semaphore contains suitable events. So in summary, semaphores can be signaled and/or consumed from; signaling is a non-blocking operation, typically initiated from an active object, events created by the signaling operation, are consumed in the normal way, usually involving block-able operations.